Zero Downtime
How can downtime of virtual servers be avoided or eliminated?
Problem
It is challenging to provide zero downtime guarantees when a physical host acts as a single point of failure for virtual servers.
Solution
A fault tolerance system is established so that when a physical server fails, virtual servers are migrated to another physical server.
Application
A combination of virtual server fault tolerance, replication, clustering and load balancing are applied and all virtual servers are stored in a shared volume allowing different physical hosts to access their files.
Mechanisms
Audit Monitor, Cloud Storage Device, Cloud Usage Monitor, Failover System, Hypervisor, Live VM Migration, Logical Network Perimeter, Physical Uplink, Resource Cluster, Resource Replication, Virtual CPU, Virtual Disk, Virtual Infrastructure Manager, Virtual Network, Virtual RAM, Virtual Server, Virtual Switch, Virtualization Agent, Virtualization Monitor
Compound Patterns
Burst In, Burst Out to Private Cloud, Burst Out to Public Cloud, Cloud Authentication, Cloud Balancing, Elastic Environment, Infrastructure-as-a-Service (IaaS), Isolated Trust Boundary, Multitenant Environment, Platform-as-a-Service (PaaS), Private Cloud, Public Cloud, Resilient Environment, Resource Workload Management, Secure Burst Out to Private Cloud/Public Cloud, Software-as-a-Service (SaaS)
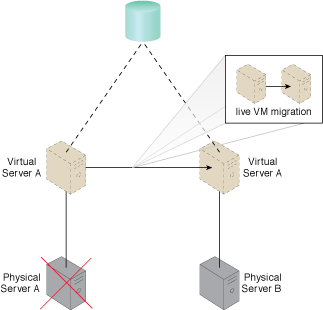
Physical Server A fails, triggering the live VM migration program to dynamically move Virtual Server A to Physical Server B.
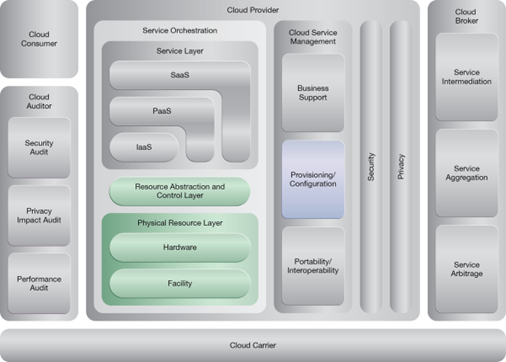
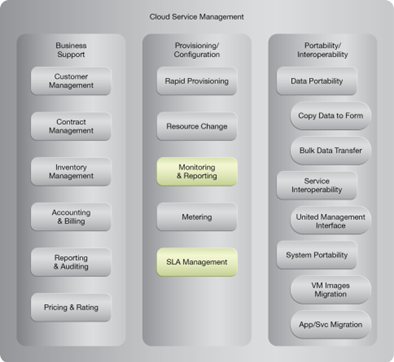
NIST Reference Architecture Mapping
This pattern relates to the highlighted parts of the NIST reference architecture, as follows: